[size=100][b](1)简述贝叶斯公式原理。[/b][/size]
[b] (2)朴素贝叶斯大数据算法操作实践。[/b][br][br] ① 作业目的。[br][br] a. 理解朴素贝叶斯算法原理;[br][br] b. 掌握朴素贝叶斯算法框架;[br][br] c. 掌握常见的高斯模型、多项式模型和伯努利模型;[br][br] d. 能根据不同的数据类型,选择不同的概率模型实现朴素贝叶斯算法;[br][br] e. 针对特定应用场景及数据,能应用朴素贝叶斯解决实际问题。[br][br] ② 作业准备。[br][br] Orange3 [color=#0000ff][b][url=https://orangedatamining.com/download/]软件下载[/url][icon]/images/ggb/toolbar/mode_zoomin.png[/icon][/b][/color]并安装。[br][br] Iris 数据集下载采用 Orange3 平台自带数据库。[br][br] 实现样本的分类,需要通过计算条件概率而得到,计算条件概率的方法称为贝叶斯准则,其计算方法为[br] [math]P\left(B\mid A\right)=\frac{P\left(A\mid B\right)P\left(B\right)}{P\left(A\right)}[/math][br][br] 朴素贝叶斯分类器,其核心方法是通过使用条件概率来实现分类,应用贝叶斯准则可以得到[br][br] [math]P\left(c_i\mid x,y\right)=\frac{p\left(x,y\mid c_i\right)p\left(c_i\right)}{p\left(x,y\right)}[/math][br]
[br] 数据集说明:Iris 数据集包含 150 个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以 Iris 数据集是一个 150 行 5 列的二维表。通俗地说,Iris 数据集是用来给花做分类的数据集,每个样本包含了 sepal_length(花萼长度)、sepal_width(花萼宽度)、petal_length(花瓣长度)、petal_width(花瓣宽度)四个特征(前 4 列),[size=100]我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。样本库的局部截图[/size]如下图所示。[br][img]https://s21.ax1x.com/2025/02/11/pEnOefS.png[/img][br][br] ③ 作业内容。[br][br] a. 实现高斯朴素贝叶斯算法;[br][br] b. 熟悉 Orange 可视化的朴素贝叶斯算法;[br][br] c. 针对 Iris 数据集,应用 Orange 可视化朴素贝叶斯算法进行类别预测;[br][br] d. 针对 Iris 数据集,利用各种参数对朴素贝叶斯算法进行类别预测。[br][br] Ⅰ. 取前两个特征值,如图 2-3-5 所示[color=#0000ff]。[/color][br][br][br]

[size=100][justify] 图 2-3-5 GaussianNB 对鸢尾花数据的分类结果[/justify][/size]
[br] Ⅱ. 取后两个特征值,如图 2-3-6 所示。
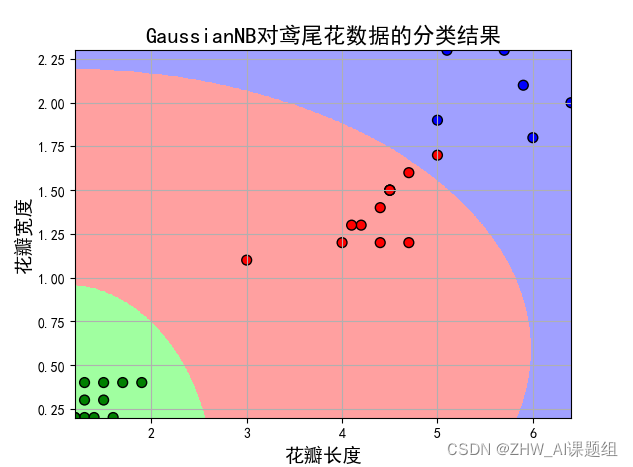
[size=100] 图 2-3-6 GaussianNB 对鸢尾花数据的分类结果[/size]
[br] Ⅲ. 撰写数据测试报告。[br][br]